目前我找到的openclawd最省token方法

痛点:Moonshot Kimi K2.5 配额吃紧,成本上升
很多人在用 OpenClaw 跑 Kimi K2.5 作为主力模型时,发现 Moonshot 官方 API 的免费/低配额很快就用完,尤其是思考模式(reasoning)开启后,token 消耗非常恐怖。
有没有办法几乎无限免费使用 Kimi K2.5,同时又不牺牲稳定性?
答案是:接入 NVIDIA 提供的 Kimi K2.5(完全免费、无限额),把 Moonshot 官方通道作为 fallback,并在模型请求超时时自动切换。
核心思路
- 主模型:
nvidia/moonshotai/kimi-k2.5(NVIDIA 免费通道,速度稍慢但 0 成本) - 备用模型:
moonshot/kimi-k2.5(官方通道,速度快但有配额) - 超时自动切换:OpenClaw 原生支持 fallback,当主模型请求超时/失败时自动切到备用
步骤详解(2026 年 3 月实测有效)
1. 获取 NVIDIA API Key(完全免费)
访问:https://build.nvidia.com/moonshotai/kimi-k2.5
登录 NVIDIA 账号 → 页面自动生成或创建 API Key(格式 nvapi-xxx...)
2. 配置 openclaw.json(最关键部分)
编辑 ~/.openclaw/openclaw.jsonmodels:
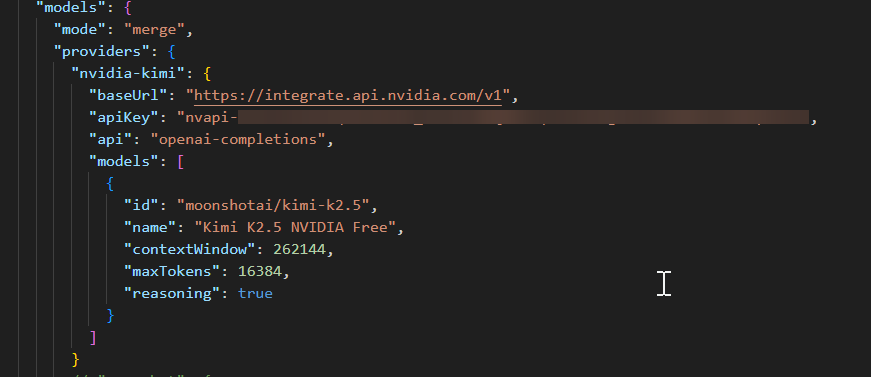
1 | |
注意1:如果你的 json 里有 agents.defaults.models(allowlist),请删除它,否则会限制只能用白名单模型,导致 fallback 失效。
注意2:kimi api最好是达到Tier1及以上(即累计充值10美元),否则很容易受到限制。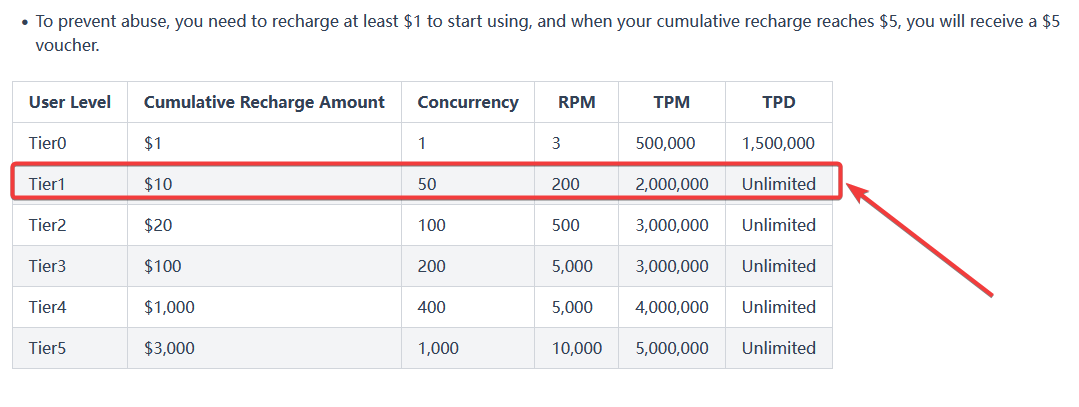
3. 设置 NVIDIA API Key(最常出错的地方)
OpenClaw 对自定义 provider 的 key 管理很严格,必须写入 agent 的 auth-profiles。
1 | |
验证:
1 | |
4. 重启并测试
1 | |
在 Telegram / Discord bot 中测试:
- 问一个复杂问题(比如多步推理、代码生成)
- 第一次可能慢 15–40 秒(NVIDIA 免费通道特性)
- 如果超时或失败,会自动切到 Moonshot 官方通道
想强制测试 fallback,可以临时把 NVIDIA key 改错再问。
5.添加自动切换或分时段切换功能(可选)
**注意这是一个可选的步骤:**我在想,有没有更便捷的方式,因为毕竟免费的nvidia/moonshotai/kimi-k2.5还是比较卡的,特别是晚上,可不可以白天自动切换使用/moonshotai/kimi-k2.5晚上自动切换使用nvidia/moonshotai/kimi-k2.5,后者,按照如果相应速度超过10秒来区分,默认使用免费版api,卡顿10秒切换为官方api呢?理论上是可以的,并且把要求向openclaw提出,它就会自己实现。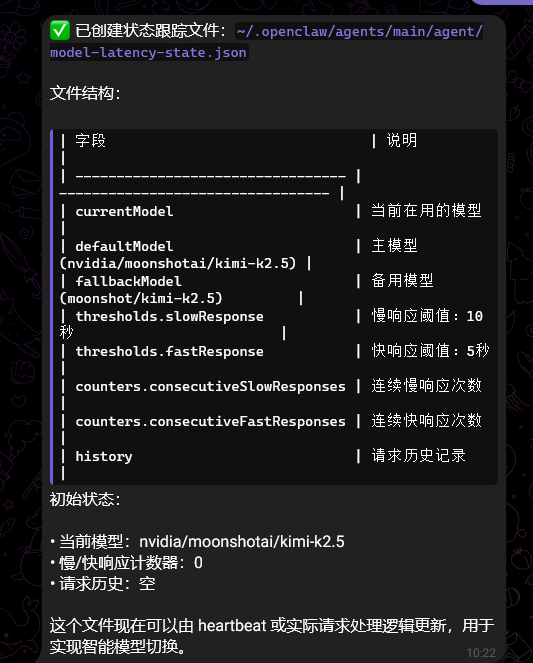
当然,手动通过/model命令来切换模型也不那么麻烦,看你自己选择了。
常见坑 & 解决
| 问题 | 现象 | 解决 |
|---|---|---|
| No API key found for provider “nvidia-kimi” | 之前用 /models 选过 nvidia-kimi | 清 sessions/cache、重设 primary 为 nvidia/… |
| Request aborted / timeout | NVIDIA 通道慢或网络问题 | 正常现象,fallback 会接管 |
| 还是走 Moonshot | allowlist 限制 | 删除 agents.defaults.models |
| thinking 不显示 | reasoning: false | 确保两个模型都设 reasoning: true |
总结
- 日常 90%+ 流量走 NVIDIA → 几乎 0 token 成本
- 复杂任务 / 超时自动切 Moonshot → 保证可用性
- 支持多模态 + 思考链 → 功能完整
我自认为,目前(2026 年 3 月)这是 OpenClaw 用户薅 Kimi K2.5 羊毛最稳定、省钱的组合。如有其他,欢迎赐教!